Sign up for dispatches from our public workshop
How and Why We Made Recovered Factory Multilingual
Invest in production and don't worry about parity. Here's the stack and the thinking behind a multilingual independent publication.
April 2, 2026 · David Eads · Edited by Ash Ngu, Tory Lysik
A core value of this project is supporting multiple languages. If internet and computing technologies have the potential to liberate people and create a more equitable world, translating human language might be one of the best things they can do.
And yet multilingual digital publishing is primarily the domain of large organizations that can accept clunky and expensive solutions. If you want to seriously publish in more than one language, not as an afterthought or symbolic gesture, you will discover this very fast.
I’ve been doing a lot of it lately: For Recovered Factory, for a big forthcoming client project, and for Luna Limón. I’ve been struck more than ever by the mismatch between our globalized world with powerful machine translation tools compared to the weak support and high cost of producing content in multiple languages in popular content management systems.
This is the first edition of Recovered Factory’s bench notes, where we get into the technical decisions and principles behind what we’re building and get into the specifics of the craft.
Bench notes will often include abbreviated sample code, but you can skim or skip those parts if you’re here for the architecture and not the plumbing. If you are into that kind of thing, our full code is open and you can use it for reference or in your own projects.
Our first edition will look at why we’re publishing this newsletter and site in English and Spanish and what we’ve learned so far. Future posts will explore the technology struggles, processes, validation techniques, and the new roles for translators involved in adding multilingual support for a fairly big institution running an older Drupal site with lots of content and their own special lingo (e.g. “curate” as in “member of the clergy” and not the verb “to curate”).
Why multilingual from day one?
Latin America is playing an increasingly important and innovative role in global news, data, and investigative journalism. This growth has been driven by economic development, broad use of cell phones, the success of social media news shows like La Pulla, and the emergence of large-scale collaborative projects like Amazon Underworld and Quinto Elemento Lab.
At Recovered Factory, we want to be a real destination for Latin American data journalists. We know there is a genuine hunger for material like this beyond the US. And we want to connect with and serve these audiences, so we’re making a bet and building RF to be multilingual from day one.
And it goes beyond just data journalism. During Bad Bunny’s Superbowl halftime show, I loved when he said “God Bless America” and then proceeded to recite practically all the countries in the Americas.

Sitting in Colombia writing this, I feel it more than ever: The Americas are a shared system that the US is less separate from than it often thinks. As Patrick Iber wrote, “It may make sense to think of the United States as a wealthy Latin American country, rather than an offshoot of Europe mysteriously governed by cowboys.”
But even though the world is more interconnected than ever and machine translation has gotten pretty darn good (hello, DeepL!), the production tools and processes for multilingual publishing feel like they’re lagging quite a bit. Given that fundamental friction, how do you make a modern publishing and subscription setup work in more than one language without creating a total mess?
Forget about parity
The most important decision we made was this: we don’t require strict parity. We don’t even require loose parity. We don’t require it between languages. Or between email and web. Or between social platforms.
Spanish goes live when it’s ready. A post on the site doesn’t have to match an email exactly. Not every piece has to appear in both languages at the same time, in the same form, or even at all. An email might bundle three posts together, or tease a longer piece on the site, or exist entirely on its own.
This post that you’re reading is a great example: Our email this time doesn’t repeat the content here but instead links to it and includes some project updates. We’ll publish a version in Spanish in the next few weeks with an entirely different email than we used for English. We’ll need a different version of this paragraph in Spanish, too.
Once you let go of the idea that every piece of content must be mirrored across your primary channels and in every language, the whole system gets simpler and the content gets better. You can do what makes sense given your resources and audience needs.
That’s because translation doesn’t work that way, anyway. Translation is not simply making a copy and transcribing it in another language. Things land differently in different languages. Sometimes publication timing matters more in one language than another. Visuals like photos, charts, and screenshots need to be localized. Sometimes landing on the right translated version takes longer because you are trying to preserve tone, rhythm, or context instead of rushing out a stiff copy.
A small but striking example: When we translated our beloved logo artist’s description of his work using DeepL, the English translation was perfectly accurate and yet felt too abstract. Suku’s original quote read fine in Spanish to me and everyone I asked, but the English needed more editing to be clear and impactful. For this reason, the Spanish version hews more closely to the original quote, while the English takes more liberties to achieve the same impact.
The same is true across platforms. Email is its own medium. The web is its own medium. Social is its own medium. A system that insists on too-much parity across all of them isn’t just technically awkward — it’s editorially clumsy.
Ultimately, we had to abandon using popular, supposedly-easy publishing tools and build our site ourselves in order to accept that reality, instead of fighting it.
Mapping our needs
Our needs were and are pretty simple:
- Email newsletter:
- Segmenting and targeting email subscribers by language.
- Language-specific signup (e.g. forms that correctly tag subscribers when they sign up).
- Website
- A multilingual site with language detection and simple language switching.
- The capability to link English and Spanish versions of content like the about page and individual posts.
- Easy divergence between languages, e.g. showing one form in the Spanish version of the site and a different form in English. Having some posts in one language, but not the other.
Shouldn’t be that hard, right? But after doing some detective work, we found the options for a small publisher are still pretty limited.
True Detective Season 5: Newsletter Country
We put on our detective hats and did a bunch of research, hoping that one of the mainstream platforms like Substack might handle our seemingly simple needs. But Substack, Ghost, and Beehiiv all required serious hacks to work. Ultimately we landed on Kit.com (formerly ConvertKit) for its good editor, robust subscriber segmenting, and developer-friendly tooling.
Substack and Ghost both require separate newsletters for each language, with each site manually cross-linked. If you want language negotiation, you’ll also need some glue code at a custom root domain to send users to the right version. That also leaves you managing multiple subscription databases. With Ghost, it also means paying for and maintaining multiple accounts. That’s not a problem with Substack since it is free to use but part of the reason it’s free is that it profits from ads in disturbing neo-Nazi and white supremacist newsletters. Beehiiv’s user segmenting seemed better, but we still needed to build a custom site and their unfortunately weak programmatic integration revealed key functionality like native subscription forms to be basically infeasible in my tests.
Of the more venerable platforms, Mailchimp was out early because I’d prefer not to use an Intuit product, and I’ve never warmed to their content editor. I didn’t deeply explore Constant Contact as an option for us, though I suspect it can handle our use case as well. And one advantage of Constant Contact is a purity of mission. It doesn’t try to be your website and store the way Kit does.
But Kit ultimately won out based on 1) novelty because I’ve used Constant Contact in the past and wanted to try something new and 2) sufficiently robust developer support that made hacking around the limitations more palatable.
My research haunted me in ways I hadn’t expected. It had been more than a few years since I looked seriously at email platforms and I expected to see better multilingual support. The past, it turns out, is always with us. Time is a flat circle. And Matthew McConaughey showed up.
One of the more notable English-and-Spanish newsletter setups I found in the wild belongs to Matthew McConaughey. And it runs on Kit, who love to highlight it in their marketing.

The McConaughey comparison is more than a joke, even if his weird AI-powered musings (”Lyrics of Livin’” which we must admit we like) are a little hard to take seriously.
McConaughey is from South Texas, where he picked up some Spanish growing up (the Americas are a shared system!) and he and his team must see the same value of publishing in Spanish that we do. They also seemingly came to the same conclusions about which newsletter platform best supports publishing in multiple languages. Seeing McConaughey’s setup was evidence of something I’d already suspected: Kit is one of the few platforms presently serving creators where this is even possible, precisely because many of the others fall into a thicket of hacks when you try.
The stack
For Recovered Factory, the setup looks like this:
- SvelteKit for the custom frontend.
- Markdown files for content storage and publishing.
- Paraglide JS (and the InLang message format) for translated interface strings.
- Kit for subscriber management and email infrastructure.
- Stripe for payments.
- Programmatic subscriber tagging to track language preferences and other metadata.
- Manual DeepL translation and extensive human editing.
The key idea is that no platform does everything. We chose specific tools for specific jobs, then connected them ourselves. We’re using plenty of AI and automation, but we’re making sure we check those outputs carefully with human review at every stage — especially when it comes to the final quality assurance.
Why a custom frontend?
None of the newsletter platforms I evaluated could handle multilingual publishing without kludges. (The full platform-by-platform breakdown is in the appendix if you’re curious.) The short version: Ghost, Beehiiv, Kit, and the rest all assume a monolingual world when it comes to their web CMS features.
That meant building a custom site. Of all the options, Kit had a robust enough API to support what I needed: a custom frontend talking to a newsletter and subscription backend. Kit handles subscriber management, automations and basic newsletter plumbing. The site and custom codebase handles everything public-facing on the web.
The core tradeoff is obvious: the dream of sending out the email and having it just appear on a decent website built and maintained by the platform is completely out the window. But we get to optimize each platform for what it’s good at, and that tradeoff has been worth it.
How Kit handles two languages
The multilingual setup in Kit comes down to segments and forms.
Segments: We created two subscriber segments — lang-en and lang-es — that track each subscriber’s language preference. When we send a newsletter, we target the appropriate segment. A subscriber can be in both, and we can craft different emails for each language or send a bilingual edition when that makes sense.
Forms: We built two separate Kit forms, one for English and one for Spanish, so that confirmation messages, welcome sequences, and other automated responses are localized. The frontend calls a little API endpoint, which in turn submits the form to Kit (direct submission from a browser is prohibited by CORS). The subscriber never sees a language picker or makes a manual choice — the site handles it.
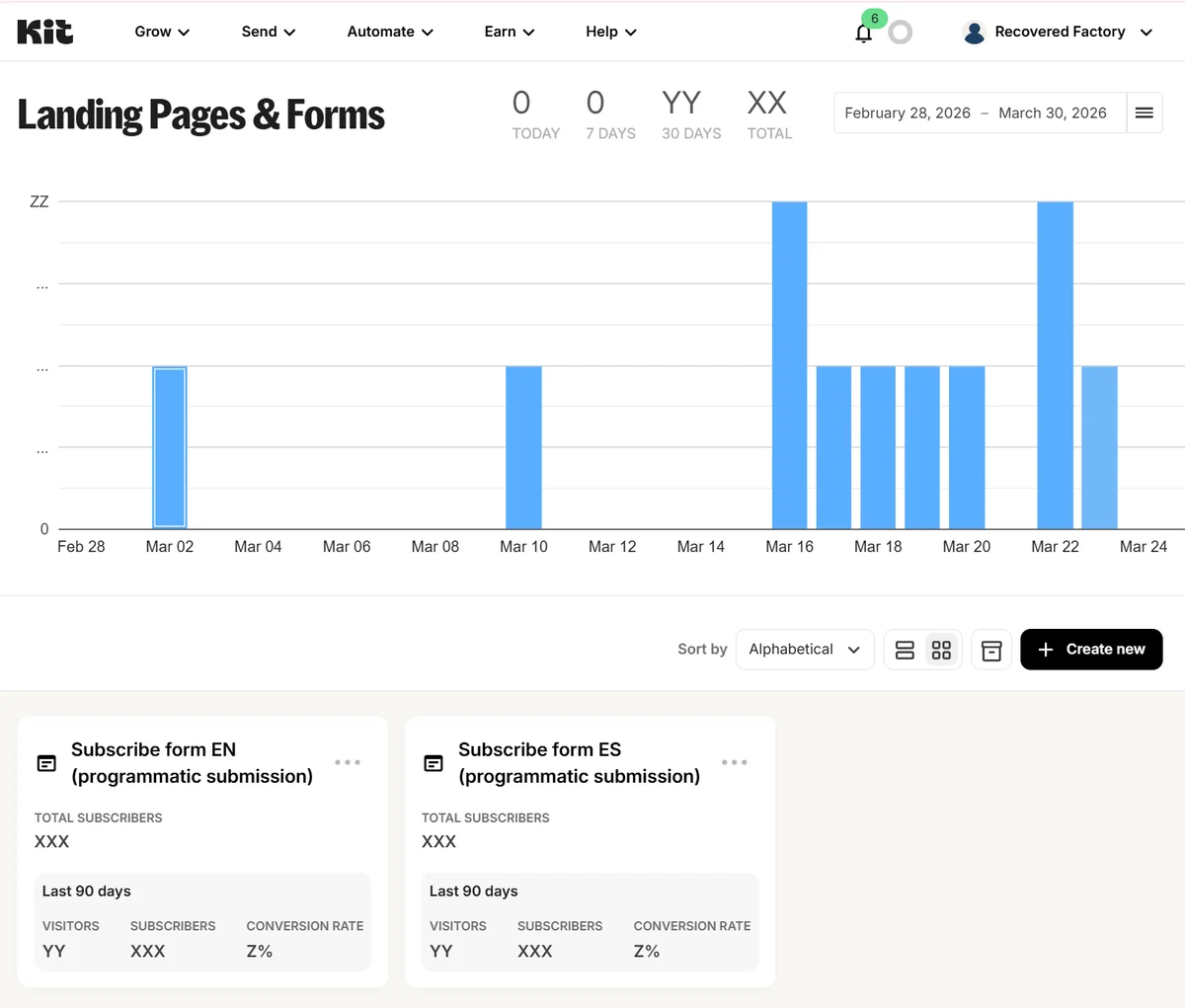
These forms are empty shells, the frontend handles every aspect of the display. But each one has a unique ID, localized automated confirmation message, and needs to redirect back to our custom site. In the Kit UI, you can see them under the “Grow” tab, in the “Landing Pages & Forms” section underneath the activity chart.
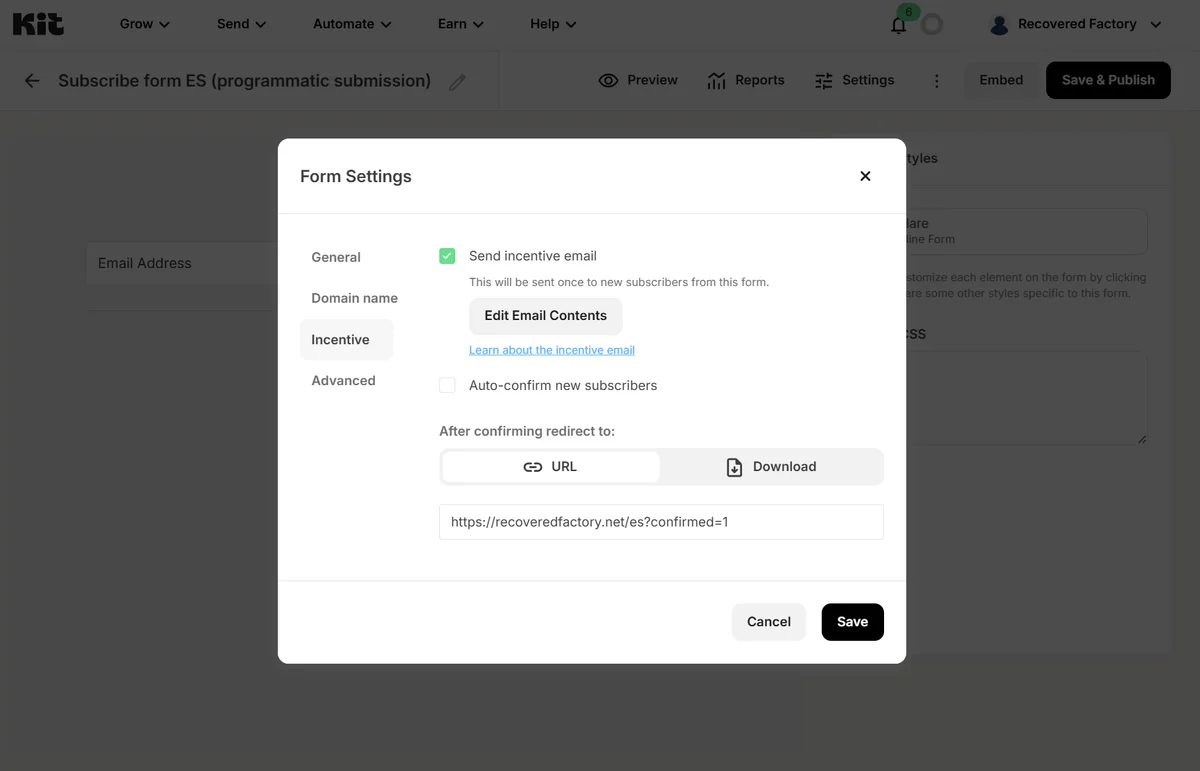
In the “Incentive” section of each form’s settings, you must set up the redirect (in this case, to the /es path on the site because this is the Spanish form) and edit the automatic response email.
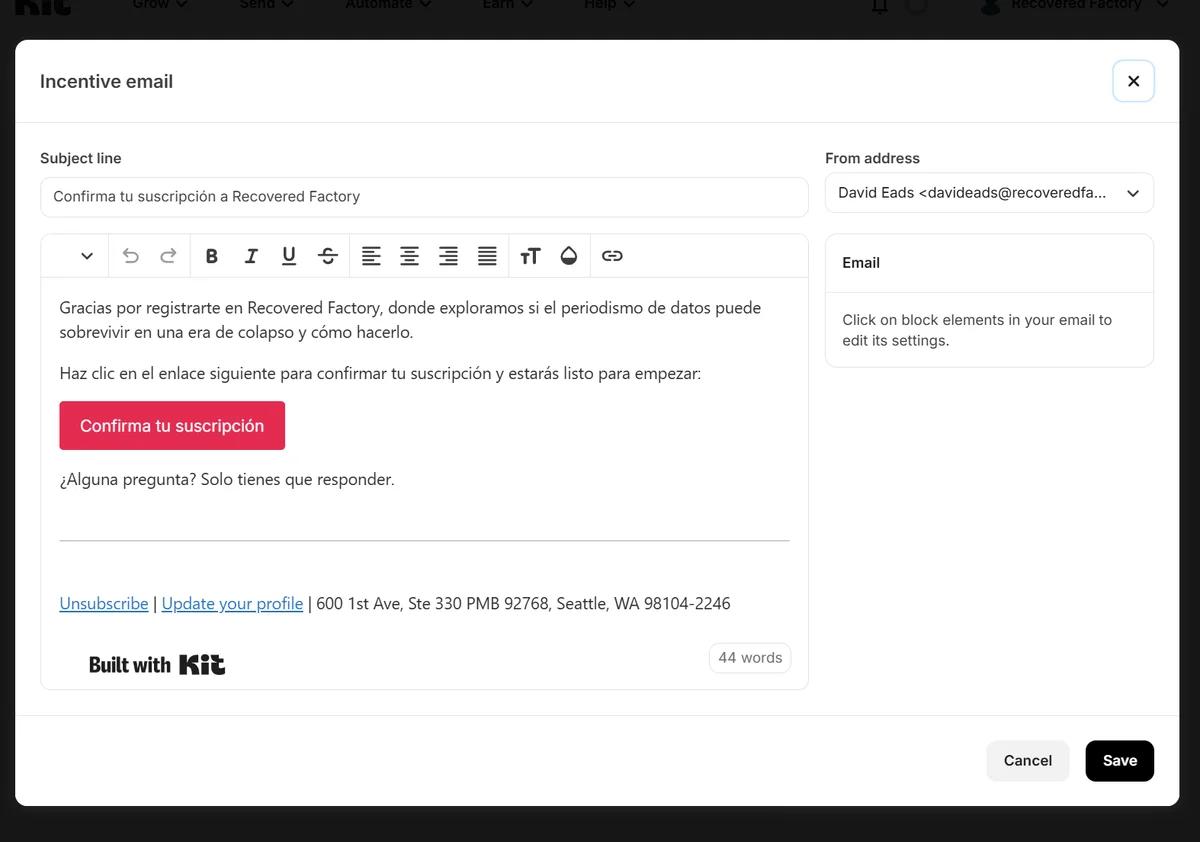
And then we need to customize the automated confirmation email in the language the form represents.
On the website side, we render a form and then run a tiny API endpoint that handles POSTing subscription data to Kit. If implementing yourself, you’ll want to note that Kit sometimes requires a captcha challenge on submit and much of the programming logic must account for that.
Here’s a simplified version of the form component (src/lib/components/SubscribeForm.svelte relative to the Sveltekit codebase):
<script lang="ts">
type Props = {
lang: string;
source: string;
};
let { lang, source }: Props = $props();
let status = $state<'idle' | 'loading' | 'success' | 'error' | 'guard'>('idle');
let errorMessage = $state('');
const handleSubmit = async (event: SubmitEvent) => {
event.preventDefault();
if (status === 'loading') return;
status = 'loading';
const form = event.currentTarget as HTMLFormElement;
const formData = new FormData(form);
formData.set('lang', lang);
formData.set('source', source);
try {
const response = await fetch('/api/signup', {
method: 'POST',
body: formData,
headers: { accept: 'application/json' },
});
const payload = await response.json().catch(() => ({}));
if (!response.ok || payload?.ok === false) {
if (payload?.guard) { status = 'guard'; return; } // bot check required — handle separately
throw new Error(payload?.error || 'Something went wrong.');
}
status = 'success';
form.reset();
} catch (err) {
status = 'error';
errorMessage = (err as Error)?.message || 'Something went wrong.';
}
};
</script>
<form action="/api/signup" method="post" onsubmit={handleSubmit}>
{#if status === 'success'}
<p role="status">You're subscribed!</p>
{:else if status === 'guard'}
<p>Please complete the verification step.</p> <!-- bot check UI goes here -->
{:else}
<input name="email_address" type="email" placeholder="your@email.com" disabled={status === 'loading'} />
<input name="lang" type="hidden" value={lang} />
<input name="source" type="hidden" value={source} />
<button type="submit" disabled={status === 'loading'}>Subscribe</button>
{#if status === 'error'}
<p role="alert">{errorMessage}</p>
{/if}
{/if}
</form>And here’s a simplified version of our little API endpoint (src/routes/api/signup/+server.ts relative to the Sveltekit codebase):
import { json, redirect } from '@sveltejs/kit';
const FORM_IDS = {
en: 'XXXXXXX',
es: 'YYYYYYY',
} as const;
const resolveLang = (value: string) => (value === 'es' ? 'es' : 'en');
export const POST = async ({ request }) => {
const formData = await request.formData();
const email = String(formData.get('email_address') ?? '').trim();
const lang = resolveLang(
String(formData.get('lang') ?? formData.get('fields[lang]') ?? 'en').toLowerCase(),
);
const body = new URLSearchParams();
body.set('email_address', email);
body.set('fields[lang]', lang);
const response = await fetch(
`https://app.kit.com/forms/${FORM_IDS[lang]}/subscriptions`,
{
method: 'POST',
headers: {
'content-type': 'application/x-www-form-urlencoded',
},
body: body.toString(),
},
);
const responseText = await response.text();
const ok = response.ok || (response.status >= 300 && response.status < 400);
// Next: parse response from Kit and decide how to respond to the client;
// primary outcomes are success + redirect, captcha ("guard"), send back error message
};How we produce and edit in two languages
While there’s a temptation to try to put production “on the rails” to lower the effort required, we’ve largely gone the manual route. For example, we could try to hit the DeepL API and generate a translation from our original Google Docs or in our content management system. We could try to write glue code to synchronize the Google Doc with a Markdown file.
We don’t do any of that stuff! We use DeepL to translate, but with a human in the loop at every step including initiating translation. Typically, I won’t try to even translate a whole article, but instead a few connected paragraphs, check the output, and continue. Then we run it by a native Spanish speaker (Diana Vanessa Riascos-Gamez mostly) for final edits.
InLang, Paraglide JS and translated UI strings
The other major piece is the InLang translation format and Paraglide JS, and it’s a big deal.
Paraglide gives you a sane, developer-friendly way to manage translated interface strings without turning your application into a haunted house of brittle i18n hacks. It’s part of the broader InLang ecosystem, and it’s extremely good — so good that it could make you consider using a JavaScript framework just to get access to it.
For Recovered Factory, the number of translated UI strings is still small enough that we simply edit them in InLang’s native JSON messages format alongside the code. Each language gets a JSON file with key-value pairs for things like navigation labels, button text, form placeholders, and other interface copy.
It’s as simple as creating messages/es.json and messages/en.json:
{
"$schema": "https://inlang.com/schema/inlang-message-format",
"site_name": "Recovered Factory",
"nav_about": "Acerca de",
"nav_donate": "Apoyar",
"nav_signin": "Iniciar sesión",
"nav_subscribe": "Regístrate",
"nav_menu_open_aria": "Abrir menú de navegación",
"nav_menu_close_aria": "Cerrar menú de navegación",
...
}{
"$schema": "https://inlang.com/schema/inlang-message-format",
"site_name": "Recovered Factory",
"nav_about": "About",
"nav_donate": "Support",
"nav_signin": "Sign in",
"nav_subscribe": "Sign up",
"nav_menu_open_aria": "Open navigation menu",
"nav_menu_close_aria": "Close navigation menu",
...
}Then, you import the messages as a function or functions. For example, in a Svelte component, you could do something like this:
<script lang="ts">
import { m } from '$lib/paraglide/messages';
</script>
<h1>{m.site_name()}</h1>Because of Paraglide’s ingenious architecture and InLang’s simple translation format, all translation strings become tree-shakeable functions, meaning only the messages you actually use go into your final build. And it works whether you’re rendering server side or dynamically.
That said, I’ve found Paraglide requires some trickery when you integrate it with more CMS-like workflows — typically by generating the translation JSON files based on transforming source data, e.g. when you have text_en and text_es variants representing the same string in different languages in a single database row. But the friction between storing translation strings “side by side” and using per-language message files is true for older, fussier systems like the old .po (Portable Object) files used by Gnu gettext.
We have other projects where we’re generating translation files from Airtable and Google Sheets that story translations side-by-side, which scales better when you have more strings or non-developer collaborators managing translations, but requires an additional step to generate the message files, and usually implies a level of complexity that benefits from adding more advanced language debugging affordances to your codebase. We’ll cover this in more detail in a future post.
Markdown content with shared IDs
The content itself lives as Markdown files, and here’s where things get a little chaotic.
Each post exists as a separate markdown file per language. They’re linked by a shared ID in the frontmatter, so the site knows that how-we-went-multilingual.md and como-nos-hicimos-multilingue.md are the same piece. The site uses that shared ID to generate language-switcher links and to know when a translation exists.
The content is then organized into Markdown files segregated by language in the directory structure: src/content/en and src/content/es relative to the Sveltekit codebase.
Here’s what the frontmatter looks like. Note the shared ID and independent fields (there are different Spanish editors than English).
src/content/en/muscle-memory.md:
---
id: "rf-muscle-memory"
title: "Muscle Memory"
date: "2026-01-28"
description: "Journalism's habits were built for a world that no longer exists. Pretending we can serve everyone equally just hides tradeoffs we're already making."
type: "post"
byline: "David Eads"
editors:
- "Tory Lysik"
tags:
- "field-notes"
lang: "en"
previewImage: "/images/factory-default--white-bg.png"
hidePreview: true
---
... post body ...And src/content/es/memoria-muscular.md:
---
id: "rf-muscle-memory"
title: "Memoria muscular"
date: "2026-01-28"
description: "Los hábitos del periodismo se crearon para un mundo que ya no existe. Fingir que podemos servir a todo el mundo por igual solo oculta las concesiones que ya estamos haciendo."
type: "post"
byline: "David Eads"
editors:
- "Tory Lysik"
- "Diana Vanessa Riascos-Gamez"
tags:
- "field-notes"
lang: "es"
previewImage: "/images/factory-default--white-bg.png"
hidePreview: true
---
... post body ...This isn’t perfect, by any means. This approach makes it easy to handle multi-lingual post slugs and tracking back to the source file from a URL like https://recoveredfactory.net/es/como-nos-hicimos-multilingue is trivial. On the other hand, we needed to write a little script to generate a crosswalk between the posts, because it’s not obvious just looking at the English and Spanish content directories what the other language’s equivalent Markdown file is.
Another approach would have been to encode the canonical ID in the filename and represent the published slug in the frontmatter. This would consist of files like how-we-went-multilingual-en.md and how-we-went-multilingual-es.md.
In the end, I felt the decision was a bit of a coin flip. Both are reasonable choices, each with their own small tradeoffs, so I went with the version that simplifies the website logic a bit because we don’t have to read and dynamically set the published slug which trades off with the additional complexity of needing to generate a post crosswalk. And in practice, this is rarely an issue, but it still introduces some mental friction and requires additional affordances.
There’s similarly no automated sync, no translation memory, no fancy diffing UI beyond a command line script to tell you which English posts don’t have Spanish counterparts yet. It’s a manual process. But it works fine at our current scale, and it has the advantage of being dead simple to understand: files in folders, linked by an ID.
If we outgrow it, we’ll probably move to something with a proper content database and translation workflow. For now, simplicity wins.
Some parting lessons
If you’re a small product team or publisher trying to internationalize your digital work, here are some lessons that help us successfully pull it off for Recovered Factory:
Forget about parity. Between languages, between channels, between platforms. Let each version of your content be itself. This is not a compromise — it’s better editorial thinking.
Your technical choices are constrained. If you want to be multilingual and play the independent creator game, you are going to end up building more than you may have expected. The platforms aren’t there yet. We’re betting it’s still worth it — the competitive advantage of genuinely serving multiple languages is real, and the tools are improving fast. DeepL alone has changed what’s possible, and the InLang ecosystem is a big leap forward for product integration.
Invest in production. The manual work of maintaining two languages across two platforms is real. But “real work” and “not worth it” are not the same thing. The alternative — pretending multilingual content will magically appear without accounting for production — costs more in the long run, just in less visible ways. There’s also a cost in not embracing our multilingual, globalized platform-driven world and you’re not detracting from the journalism by honestly accounting for what it takes to produce content in this world.
That’s where we are. Not a perfect system, but one that reflects how language and publishing actually work for a small, independent team like Recovered Factory and a recipe for sustainability.
Sign up for dispatches from our public workshop